

Si le succès de l’IA est dû en grande partie au logiciel, il n’est rien sans le matériel sur lequel il est développé, entraîné et déployé.
Expert - Axel Störmann, vice-président du marketing et de l’ingénierie de la mémoire, KIOXIA Europe
GmbH
En matière de technologie, la plupart des consommateurs s’enthousiasment pour les produits, mais rarement pour ce qu’ils contiennent. Cependant, l’intelligence artificielle (IA), un logiciel intelligent qui tente de reproduire la façon de penser des humains, est rapidement devenue un terme familier grâce à des outils tels que chatGPT et Midjourney. L’IA d’aujourd’hui a mûri, bien que lentement, sur trois quarts de siècle, à partir de l’étude du fonctionnement des neurones du cerveau et des machines pensantes dans les années 1940. Si le succès de l’IA est dû en grande partie au logiciel, il n’est rien sans le matériel sur lequel il est développé, entraîné et déployé.
L’apprentissage machine (Machine Learning, ML) et l’apprentissage profond (Deep Learning, DL) sont proposés aujourd’hui, des branches de l’IA qui se concentrent respectivement sur les méthodes d’analyse statistique et les systèmes d’apprentissage autonomes. L’industrie des semi-conducteurs a réagi en développant des processeurs adaptés pour fournir les performances de calcul de l’ordre du pétaflops dont dépendent ces algorithmes. Toutefois, des questions se posent quant au choix optimal de la mémoire. En effet, les besoins varient entre le stockage des données d’entraînement, les données d’entrée collectées auprès des utilisateurs et des capteurs pendant le fonctionnement, ainsi que les résultats intermédiaires calculés pendant l’entraînement et le fonctionnement.
Les défis liés au traitement des données
Bien entendu, de telles performances de traitement ont un prix et, dans notre monde où l’accès à la technologie est démocratisé, ce sont les fournisseurs de services cloud qui offrent un accès partagé à cette puissance de traitement de l’IA. Cependant, le matériel utilisé pour l’IA diffère de l’équipement nécessaire pour les serveurs qui fournissent des sites web, gèrent des bases de données et dirigent le trafic IOT , où les charges de travail et les demandes d’utilisation sont établies et bien comprises. Selon les interlocuteurs, on pense qu’un serveur destiné à l’entraînement de l’IA nécessite deux fois plus de stockage SSD et jusqu’à six fois plus de DRAM qu’un serveur cloud standard. Les livraisons de matériel adapté à l’IA devraient représenter près de la moitié des serveurs d’ici à la fin de la décennie, ce qui représente une croissance significative de la demande de mémoire.
Le défi réside dans la dynamique de la mémoire DRAM, à la fois en tant que produit et en tant que
marché. L’évolutivité a atteint une limite, ce qui signifie que nous n’obtiendrons pas de sitôt
davantage de bits par matrice de surface. L’empilage de matrices est une option, mais son coût est
plus élevé en raison, entre autres, des problèmes de rendement. L’objectif ultime est l’évolutivité
grâce aux puces 3D, une avancée qui a transformé l’industrie de la mémoire flash. Mais même si les
technologies dont il est question aujourd’hui se concrétisent au cours de cette décennie, il faudra du
temps avant qu’elles ne fassent leurs preuves et qu’elles ne s’imposent. Le marché est l’autre
problème. Les prix montent et descendent en fonction des fluctuations de la demande et de la
production. Ainsi, lorsque la DRAM semble être la solution au cours d’un trimestre, elle devient le
problème qui nous empêche d’avancer le trimestre suivant.
L’IA : des mémoires différentes selon les tâches
Plusieurs étapes doivent être suivies avant de pouvoir déployer un nouvel algorithme d’IA. Tout commence par les données nécessaires à l’entraînement de l’IA. Les ensembles de données peuvent être les collections de vidéos prises à partir de véhicules circulant dans les villes, des échantillons audio de conversations humaines ou des images provenant d’examens médicaux. Ces informations proviennent de diverses sources au début du pipeline de données de l’IA, ce qui nécessite une mémoire à écriture unique à haut débit (figure 1).
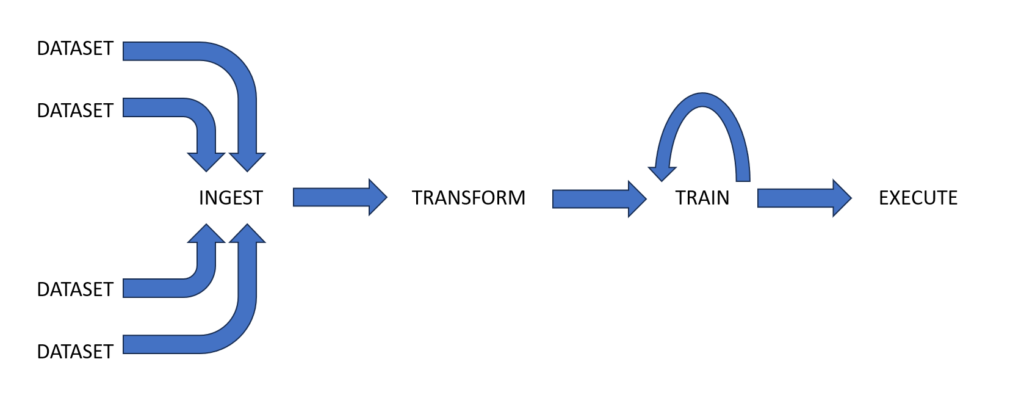
Figure 1 : Le pipeline de données d’IA peut être divisé en quatre étapes. Selon l’étape, la DRAM est souvent excessive sur le plan des performances et du coût, tandis que les disques SSD sont limités en raison de leur temps de latence.
En raison de la nature disparate des données, l’étape suivante du pipeline est le nettoyage et la transformation. Les données brutes sont triées et normalisées pour répondre aux besoins du cadre de l’IA. Les besoins en mémoire à cette étape varient en fonction des données utilisées, mais la vitesse reste essentielle. En raison du va-et-vient du processus, la répartition lecture-écriture peut se situer entre 50:50 et 80:20.
Vient ensuite le processus d’entraînement. Les données préparées sont transmises de manière répétée d’un support de stockage au matériel, un processeur de type processeur graphique (GPU) doté d’une mémoire locale à grande vitesse. Au fil du temps, l’algorithme s’améliore dans la tâche pour laquelle il a été conçu, comme la reconnaissance de tumeurs dans des images médicales. À ce stade, un système de stockage en lecture seule à grande vitesse fournit des données à une mémoire à plus grande vitesse pour la durée d’une période d’apprentissage. La DRAM est généralement choisie simplement parce qu’elle offre la vitesse requise et que l’architecture informatique la prend en charge. Cependant, la plupart des tâches de la DRAM à ce stade sont des tâches de lecture.
La dernière étape est le déploiement (figure 2), et les exigences en matière de mémoire à ce stade varient considérablement. Les utilisateurs peuvent se connecter à un serveur d’IA générative pour créer des images ou utiliser une caméra intelligente sur un drone, avec des exigences strictes en matière de coûts, de consommation d’énergie et de poids. Quoi qu’il en soit, il doit y avoir suffisamment de mémoire (principalement en lecture seule) pour stocker le modèle d’IA nécessaire à l’exécution des fonctions apprises, ainsi que de la mémoire en lecture-écriture pour traiter les résultats intermédiaires et finaux des calculs.
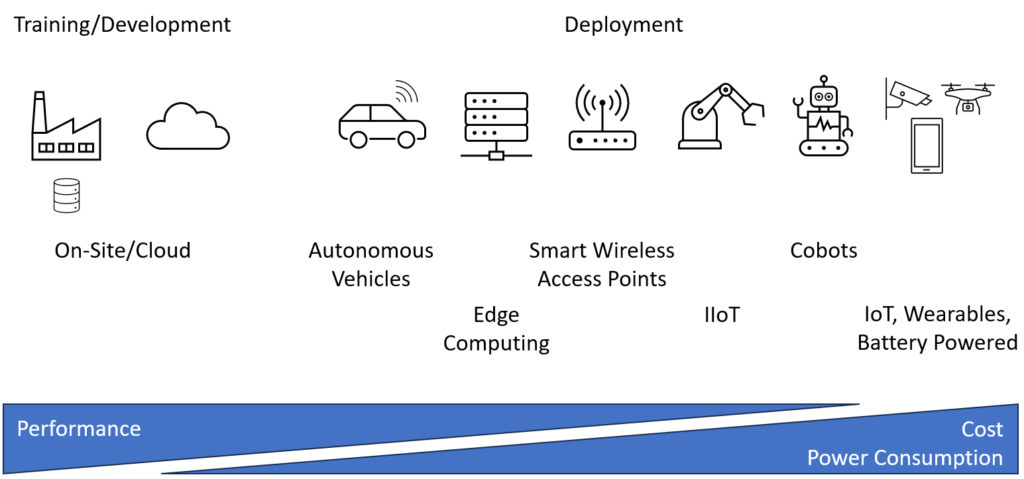
Figure 2 : Alors que la performance est la principale exigence lors de l’entraînement de l’IA, le coût et la consommation d’énergie prennent de l’importance lorsque les modèles d’IA sont déployés dans des applications.
Le fossé entre les DRAM et les disques SSD
En résumé, la DRAM offre un accès rapide aux données en lecture-écriture, ce qui, d’une manière générale, est essentiel pour accélérer de nombreux aspects du développement et du déploiement des algorithmes d’IA. Cependant, elle reste coûteuse par bit, gourmande en énergie et surdimensionnée dans de nombreuses étapes du pipeline. En revanche, les disques SSD pourraient être une option, en particulier dans les parties du pipeline où le transfert de données est intensif en lecture et exige une puissance dix fois plus faible. Les disques SSD NVMe M.2 et PCIe 4.0 de KIOXIA offrent des débits de lecture séquentielle allant jusqu’à 7 Go/s, ce qui correspond à la bande passante d’une DDR5-5600 pour un processeur (CPU) à 10 cœurs 1 . Mais le temps de latence du stockage sur disque flash (environ 100 µs) est 10 000 fois plus lent, ce qui se traduit par beaucoup de temps perdu à attendre l’arrivée des données (figure 3).
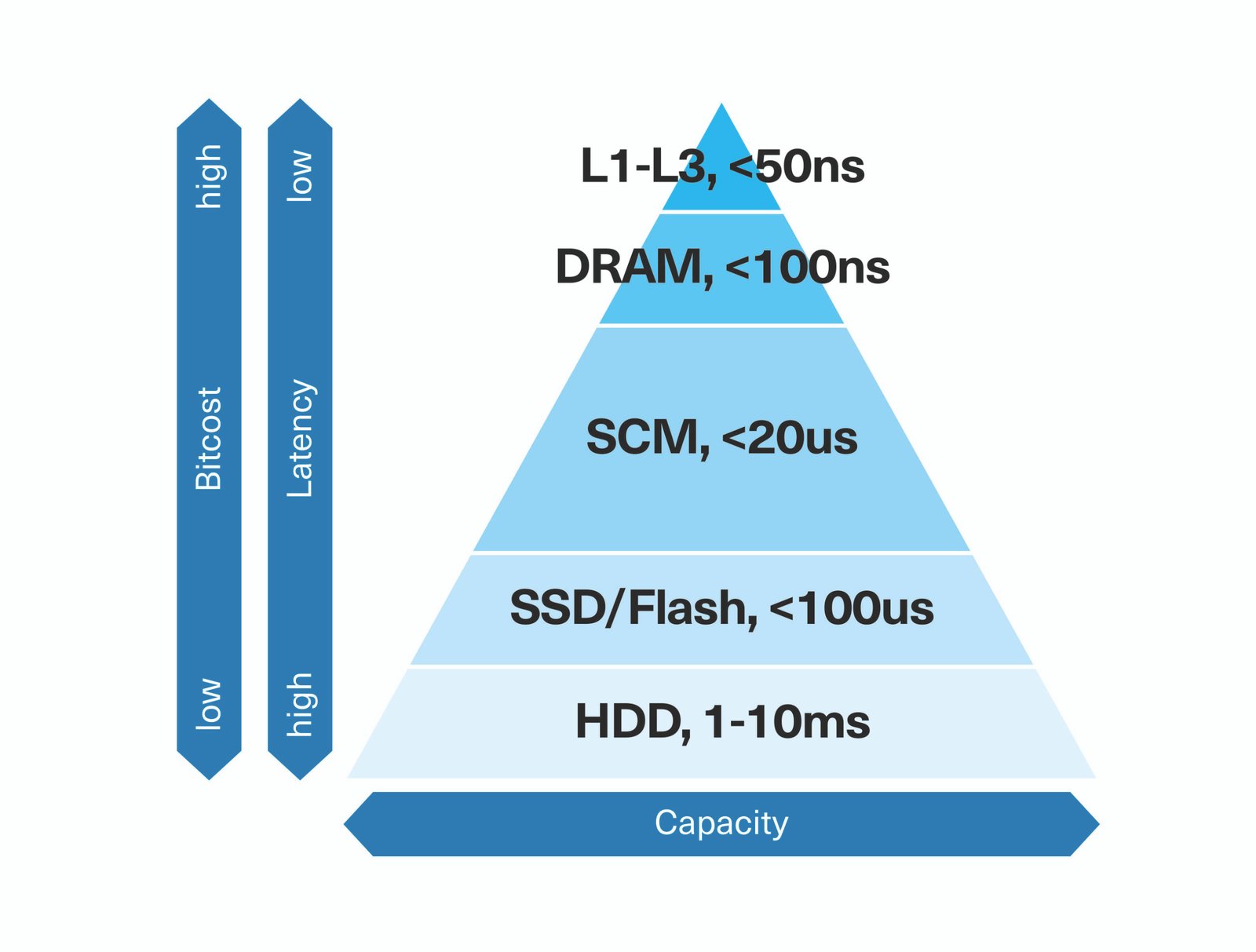
Figure 3 : Alors qu’une mémoire flash non volatile pourrait remplacer progressivement la DRAM, les disques SSD à mémoire flash classique ne sont pas une option en raison de leur temps de latence.
[KIOXIA pourrait adapter ce type de diagramme à ses besoins/son message – Tiré de : https://www.computerweekly.com/de/definition/Storage-Class-Memory-SCM]
Mais une solution de mémoire flash peut encore, dans certains cas, combler l’écart entre la DRAM à faible latence et les disques SSD à large bande passante et à faible consommation d’énergie, comme l’ont constaté des chercheurs.
Il n’est pas rare qu’un ensemble de données d’apprentissage pèse 10 To. Il faut donc plusieurs dizaines de serveurs dotés de plus de 100 Go de DRAM pour mettre en œuvre l’étape d’apprentissage. Toutefois, l’ensemble de données doit encore être lu à partir du support de stockage. Les chercheurs du Institut de technologie du Massachusetts (MIT) ont découvert que ces accès au disque ralentissaient le système à des vitesses comparables à celles de la mémoire flash.
Ils ont ensuite développé une approche combinant des serveurs avec un réseau de FPGA, chacun relié à 1 To de mémoire flash. La mise en œuvre de cette approche a offert les mêmes performances qu’une approche basée sur la DRAM tout en réduisant le nombre de serveurs à dix pour un ensemble de données de même taille, ce qui a permis de réduire considérablement les dépenses financières.
Une nouvelle couche de mémoire – SCM
Cette étude renforce les voix de ceux qui prônent la création d’une nouvelle couche dans la hiérarchie de la mémoire. La mémoire de classe de stockage (SCM) a été proposée pour combler le fossé entre la DRAM et le stockage flash afin de réduire les coûts sans nuire aux performances. Ciblant des applications telles que l’intelligence artificielle, qui accèdent en permanence à des ensembles de données gigantesques, la SCM est définie comme un type de mémoire totalement ou partiellement non volatile offrant des temps de latence de lecture inférieurs à ceux des disques SSD, à un prix inférieur à celui de la DRAM.
KIOXIA a développé XL-FLASH pour cibler cette couche de la hiérarchie de la mémoire (figure 4). Grâce à une architecture à 16 plans qui raccourcit le parcours des données sur la matrice, les temps de latence de lecture peuvent être inférieurs à 5 µs, soit dix fois plus rapides que la mémoire flash classique. XL-FLASH peut être intégrée dans des formats de stockage utilisant une interface NVMe PCIe avec une taille de page de 4 Ko, au lieu des 16 Ko offerts par un périphérique flash classique. De plus, elle est évolutive, construite sur la technologie BiCS FLASH 3D multimatricielle et offre les mêmes niveaux de fiabilité des cellules, de rapidité de lecture/programmation et de rapport prix/performances que les utilisateurs sont en droit d’attendre.

Figure 4 : La XL-Flash de KIOXIA a fait ses preuves en tant qu’alternative SCM à la DRAM dans les applications à forte densité de lecture. [Tiré de https://www.kioxia.com/en-jp/rd/technology/topics/topics-20.html]
Le défi restant consiste à intégrer cette mémoire de manière à profiter au maximum des améliorations de la latence et de la bande passante disponible. NVMe utilise PCIe pour accéder aux périphériques de bloc, mais ce protocole présente certaines inefficacités car il doit supposer que les données auxquelles on accède, les fichiers, varient en taille. Toutefois, ce n’est pas la vocation de la mémoire SCM, qui est proposée comme partie intégrante de la carte mémoire. Le Compute Express Link (CXL) est proposé comme alternative, basée sur PCIe 5 et les versions ultérieures. Il fonctionne au niveau de la couche de liaison, offrant ainsi un accès efficace aux mémoires et aux accélérateurs avec des dispositifs de mise en cache optionnels. Le protocole est plus rapide, car CXL.mem utilise la sémantique de l’octet pour accéder à la mémoire. Cela est possible car les accès sont toujours de la même taille et les périphériques apparaissent dans l’espace d’adressage de la mémoire de la même manière que la DRAM. Les architectures de processeurs Intel et Arm prennent en charge le CXL. Ainsi, que les applications d’intelligence artificielle soient déployées sur des serveurs ou des périphériques, XL-FLASH, en tant que DRAM à moindre coût et mémoire flash à faible latence, sera une option.
En résumé
Tandis que la société et les régulateurs débattent du visage public de l’IA et de la mesure dans laquelle elle doit empiéter sur nos vies, la demande de matériel optimisé pour l’IA continue de croître, afin de permettre la prise en charge des nombreuses et diverses tâches auxquelles elle est appliquée. Jusqu’à présent, la DRAM a été la mémoire privilégiée pour les serveurs et les applications finales, parce que c’est « la façon de faire traditionnelle » et non parce que c’est la meilleure solution. En analysant les différentes étapes du pipeline de données d’IA, il est clair que les étapes où les données sont « chaudes » (très fréquemment consultées et transférées) bénéficient de cette ressource coûteuse, alors que les données qui le sont moins n’en bénéficient pas. La SCM offre une solution, étant un point de latence intermédiaire entre la DRAM et les disques SSD. Associée à l’introduction du CXL, la mémoire flash à faible latence, telle que la XL-FLASH, est bien placée pour apporter des améliorations en matière de prix, de performances système et de consommation d’énergie à tous les types d’appareils, des serveurs aux périphériques déployant la puissance de l’IA.
1 https://www.crucial.com/articles/about-memory/everything-about-ddr5-ram


