Amazon Web Services vient d’annoncer la mise en service du Projet Rainier, un cluster d’IA de grande ampleur dédié à l’entraînement de modèles avancés. Déployé moins d’un an après son annonce, le projet repose sur près d’un demi-million de puces AWS Trainium2 (1 millions fion 2025 selon Anthropic), développées en interne par AWS spécifiquement pour l’apprentissage automatique.
- Nous décrivons plus bas le fonctionnement du Projet Rainier
Le projet marque une étape importante dans l’engagement d’AWS à faire progresser son infrastructure d’IA à grande échelle comme l’indique Ron Diamant, ingénieur chez AWS et architecte en chef de Trainium, « il s’agit d’un projet d’infrastructure colossal et unique en son genre qui ouvrira la voie à la prochaine génération de modèles d’intelligence artificielle. »
- Le projet Rainier tire son nom du stratovolcan de 4 392 mètres visible depuis Seattle par temps clair.
Déployée dans plusieurs datacenters aux Etats-Unis, l’infrastructure repose sur la conception d’une puce IA sur mesure (Trainium2) capable de traiter des quantités de données massives et l’interconnexion des serveurs (UltraServers) permettant une circulation des données beaucoup plus rapide au sein du système et une accélération significative des calculs complexes.

Pour y arriver, AWS a notamment collaboré avec Anthropic, principal utilisateur de ce cluster pour le développement de son modèle Claude. D’ici la fin de l’année, ce dernier devrait être installé sur plus d’un million de puces Trainium2 pour des tâches telles que l’entraînement et l’inférence, soit cinq fois plus que celles utilisées par Anthropic pour entraîner ses modèles précédents.
Comment fonctionne Rainier ?
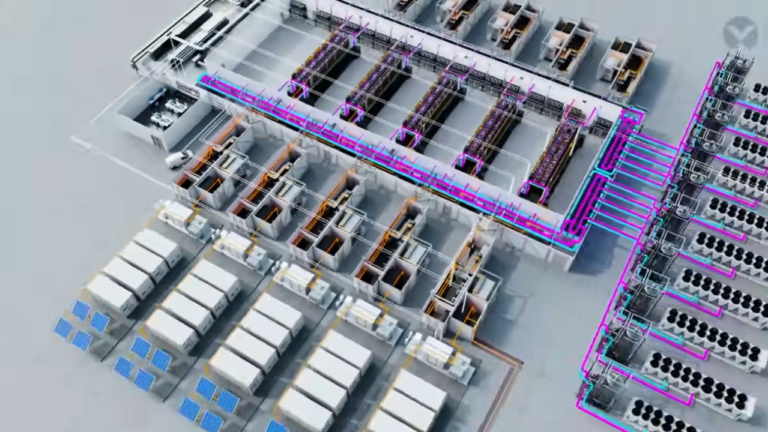
Traditionnellement, les serveurs d’un datacenter fonctionnent indépendamment. Lorsqu’ils doivent partager des informations, ces données doivent transiter par des commutateurs réseau externes. Cela introduit une latence, ce qui est loin d’être idéal à grande échelle.

La solution d’AWS à ce problème est à deux niveaux techniques d’intégration verticale :
- UltraServer – Solution de calcul d’un nouveau genre, l’UltraServer combine quatre serveurs Trainium2 physiques, chacun équipé de 16 puces Trainium2. Ils communiquent via des connexions haut débit spécialisées appelées « NeuronLinks ». Reconnaissables à leurs câbles bleus distinctifs, les NeuronLinks fonctionnent comme des voies express dédiées, permettant une circulation des données beaucoup plus rapide au sein du système et une accélération significative des calculs complexes sur l’ensemble des 64 puces.
- Elastic Fabric Adapter – La technologie réseau Elastic Fabric Adapter (EFA) (identifiable à ses câbles jaunes) connecte les UltraServers au sein d’un même centre de données et entre différents centres de données.
Le projet Rainier de méga « UltraCluster » permet de connectez des dizaines de milliers de ces UltraServers et de tous les orienter vers le même problème.
En mettant au point tous les composants de son infrastructure — de la conception des puces à l’implémentation logicielle en passant par l’architecture serveur —, AWS s’assure la maîtrise complète de la pile technologique et la résilience de ses systèmes.